Sometimes you can use Google to find information stored in a certain website or app that you can’t by using the website or app itself. I call these hacks “Google Backdoors”.
Here are five Google Backdoors I use regularly.
#1. BUSINESS FINDER
A new restaurant opened in my neighborhood. Its owner said they delivered via Swiggy, one of the leading food delivery apps of India.
I opened up Swiggy on my smartphone, entered the restaurant’s name into the search box and tapped the enter key. The restaurant didn’t show up on the next screen. I mentioned this to the owner.
He averred that a few other customers had also mentioned the same problem. He then borrowed my phone and Googled the restaurant’s name. Voila, the Swiggy result came up right on top.
I tapped the link and half expected it to take me to Swiggy’s splash screen, from where I’d need to start again, and go round and round in circles.
Thankfully, that didn’t happen. Google had used Deep Linking technology to take me directly to the said restaurant’s page on the Swiggy app.
This is a strange situation where an app creates and stores data but can’t discover that data by itself whereas Google can. I don’t know why this happens, from a technical point of view. If and when I find out, I’ll update this post with the reason.
In this example, I used this hack to discover a restaurant inside a food delivery app but I’m quite sure it will also work in a more generic context, such as to find the listing for any type of business (e.g. doctor, salon) inside the corresponding app.
#2. CONTENT SEARCH
If you’re into content marketing, you’ve posted many articles and comments all over the web.
You also find frequent opportunities to repost your past content. But you’re hampered in that pursuit because you can’t find your own pre-existing content.
Wish @disqus had a search feature à la @getliner . Over the years I've left 1350 comments on the world's most popular commenting platform. By now, it has become very painful and time consuming to browse through them manually to find reusable past comments.
— Ketharaman Swaminathan (@s_ketharaman) June 17, 2018
This might sound strange to the uninitiated but, to anyone who has experienced this, discovering your own content on the world wide web can be very painful and time-consuming.
I’ve often wished that there was an app to surface all my past content. To a content marketer like me, such an app would give a tremendous productivity boost.
Is there a @usefyi for documents in my hard disk? For my comments and other content spread out all over the web??https://t.co/32FcbGkrFo
— Ketharaman Swaminathan (@s_ketharaman) May 9, 2019
My above tweet went unanswered.
I created a strawman website for this called Archive My Content 360.
Until there’s a better app for this – startup idea? – you can use Google Site Search.
Let me illustrate this technique by trying to find my Finextra article on myBank.
For the uninitiated, Finextra is the largest fintech community in the world.
myBank is a type of payment method – very similar to NetBanking in India – that’s coming back in fashion on the back of the new Open Banking and PSD2 initiatives in the European Union.
I’ve been active on Finextra for nearly a decade, during which period I’ve published over a hundred blog posts and 3000 comments.
Finding just one article from among 100+ articles on the platform is a non-trivial task.
The browse feature on Finextra is too cumbersome. I need to browse through 10+ pages like the one on the right to find my article.
The search feature on Finextra sucks – I couldn’t find my article anywhere on its results page.
Enter Google Site Search. I simply typed the following command into the Google Search box:
site:finextra.com Ketharaman myBank
The very first result on the search results page was the link to my 2011 article entitled Why I Think EBA Clearing’s myBank Will Be A Hit.
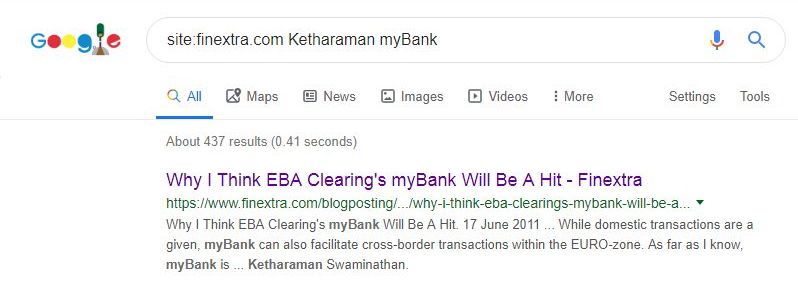
Mission accomplished!
While I’ve used this Google Backdoor to find my own content on a given website, you can use it to find anyone else’s content by entering the corresponding author’s name in your search query.
I must caveat this hack with the disclaimer that it probably won’t work on walled gardens i.e. social media updates and paywalled content. Someday, I’ll write another post on how to crack that problem. (Spoiler Alert: It’s even harder.)
I must also add that the site search problem is not unique to Finextra. The portal came to mind readily only because it’s where I use this hack most often.
Fact is, site search is broken almost everywhere on the web. If that sounds like I’m tarring the entire world wide web with the same brush, I’m not the only one.
As TechCrunch notes, “TechCrunch has published thousands of blog posts over its nearly 5 and a half years. Many are good one-day stories, some we’d like to forget, but others are gems. These classics are just as interesting today as when they were first written … But try discovering them. It’s nearly impossible.”
In 2011, I wrote Why Is It Easier To Search The WWW Than A Single Website?, highlighting this problem. A year later, I asked, only half tongue-in-cheek, Does Google Find It Difficult To Search Its Own Website?
Eight years later, for some unfathomable reason, this problem has not been solved. If anything, it has become more intractable, with Google shuttering down its solution Custom Search Engine in the interim period.
#3. PUBLICATION DATE FINDER
There are times you want to know the date of publication of a certain article or blog post (or any webpage in general) to gain extra context.
Take the Financial Brand article https://thefinancialbrand.com/72015/building-banking-branches-new-markets/ for example.
The lede of this article begins with the line “Branch expansion has become popular again.” (emphasis mine)
The boldfaced term makes this statement very time-sensitive, so I wanted to find out the date on which the article was published.
I received the link to this article in The Financial Brand e-newsletter dated 23 April 2018 but I couldn’t assume that the article was published on the same day because TFB regularly recycles its old articles.
The date of publication wasn’t mentioned on the top or in the body of the article, as some publishers do.
It wasn’t a part of its URL either, as is the default setting for a WordPress blog post. (For example, the URL of the latest post on GTM360 Blog is https://gtm360.com/blog/2019/06/14/communications-low-hanging-fruit-for-enhancing-cx/, from which you can infer – correctly! – that it went live on 14 June 2019.)
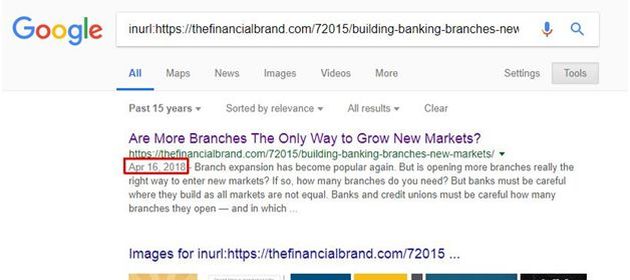
None of the obvious ways to achieve my objective worked. Then I stumbled upon the Google INURL command here.
I used this Google Backdoor to find the article publication date by following the below steps.
Google INURL Search | Find Publication Date
- Open said webpage on Chrome Browser. The URL displayed on the Address Bar is https://thefinancialbrand.com/72015/building-banking-branches-new-markets/
- Type “INURL:” (without quotes) before the displayed URL i.e.
- INURL: https://thefinancialbrand.com/72015/building-banking-branches-new-markets/
- Press ENTER
- Type “&as_qdr=y15” (without quotes) at the end of the URL you see on the Address Bar i.e. https://www.google.com/search?rlz=…&as_qdr=y15
- Solve reCAPTCHA if prompted
- The search result that follows will mention the date of publication of the article – 16 April 2018. (cf. following exhibit)
As I suspected, the article was dated well before the newsletter.
On this instance, I’ve used this Google Backdoor on an article, but it can equally well be used to find out the date on which any webpage went online.
#4. SURGE PRICE INDICATOR
 In my 2017 blog post entitled Uber Creates Loyalty To The Deal But Not For The Brand, I ranted about the way Uber hides surge pricing. Two years later, my Uber app does hint at surge pricing with the warning “Fares are higher due to increased demand”.
In my 2017 blog post entitled Uber Creates Loyalty To The Deal But Not For The Brand, I ranted about the way Uber hides surge pricing. Two years later, my Uber app does hint at surge pricing with the warning “Fares are higher due to increased demand”.
But I’m still peeved that the app does not mention the surge multiple.
Once again Google comes to the rescue.
Simply seek directions to your destination on Google Map, tap the rideshare option, and Google will show you the exact surge multiple on Uber (1.2X on this instance) and other popular ridesharing apps operating on that route.
#5. TWITTER ACCOUNT FINDER
(This hack was added a couple of weeks after the original post was published.)
Twitter now allows Google to index its content inside its walled garden. As a result, it’s possible to use Google Search to find Twitter Handles of people and companies – often more easily than with Twitter itself.
You can find a how-to guide along with a few examples in our blog post titled Two New Ways To Overcome The Twitter Identity Crisis.
Hat tip to Vikas SN (@tsuvik) for sharing this hack.
It's bizarre that the fastest way to find a Twitter account for a person or a brand even now is Google and not Twitter itself.
— Vikas SN (@tsuvik) June 19, 2019
The above list of Google Backdoors is by no means exhaustive. If you know of any more hacks, please share in the comments below.
On a side note, in my blog post entitled Never Ending Search For End Of Google Search, I’d listed three sources of traffic for Google Search viz. Product Search, Knowledge Search and Website Search.
I’m wondering if I should add Google Backdoors as one more source to that list.