In myBAR Data Analysis By ChatGPT, we saw various insights from ChatGPT based on crunching the data in myBAR dataset (For those who haven’t read that post, myBAR dataset contains ratings and reviews given by me to 600-odd books I’ve read in the last 15-odd years).
This analysis happened on data in a spreadsheet. Some vendors call CSV / XLS unstructured data whereas others call it semi-structured data. Either way, this is a canonical example of the use of ChatGPT to conduct data analysis on non-structured data. (Click here to see an example where ChatGPT did data analysis on handwritten data, which everybody would agree is unstructured data.)
I was surprised that ChatGPT missed an obvious insight into my reading behavior, namely, that I’ve an overwhelming preference for fiction over non-fiction books. But, apart from that solitary error of omission, its insights were very comprehensive, spanning two categories:
- Basic insights: Based on data in myBAR dataset.
- Advanced insights: Based on additional data fetched by ChatGPT that was not in myBAR dataset.
In ChatGPT Makes GIGO Obsolete, I’d posited that ChatGPT sources missing / erroneous data from third party data brokers. Advanced insights confirms that.
Some of these insights are FYI whereas others are actionable.
In this blog post, I’ll cover the actionable insights.

Let’s get on with it.
1. Housekeeping
While verifying the overall summary (insight #3), I discovered inconsistencies in the rating descriptors across different rows e.g. Some 3* ratings were labeled “Good: Definitely worth reading” whereas others said “Good: Worth reading”. Ergo the following:
Actionable Insight: Standardize the description of ratings.
I did this manually by replacing the wrong descriptions in the source Google Sheet with the right ones. In hindsight, I realize that I could’ve written a prompt to have ChatGPT do the heavy lifting and saved myself a half hour or so of manual work.
2. Data Cleansing
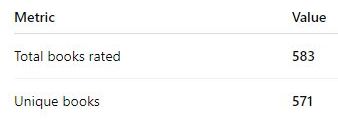 In the overall summary (insight #3), ChatGPT reported a mismatch between the counts of total books (583) and unique books (571).
In the overall summary (insight #3), ChatGPT reported a mismatch between the counts of total books (583) and unique books (571).
This suggested that there were 12 duplicate entries (583-571). Ergo the following:
Actionable Insight: Remove duplicates.
To help me in this pursuit, I asked ChatGPT to list the duplicates and point out the rows in which they’d occurred. I reviewed its response and found that:
- All of its duplicate calls were right.
- Some row calls were also right e.g. “463 & 464, FROZEN PAST, Richard Hale”.
- Some row calls were offset by a few rows e.g. ChatGPT called “EXECUTIVE POWER, Vince Flynn” on Row 33 and 38 whereas the duplication was actually in Row 35 and 40.
I de-duped these books in the original Google Sheets manually.
I then realized that some of the duplicates were not really duplicates e.g:
 The same book’s rating and review were duplicated on two different rows.
The same book’s rating and review were duplicated on two different rows.- I happened to repeat a few books after a gap of few years and reviewed them again, forgetting that I’d already reviewed them before e.g. PERFIDIA, James Ellroy; SHEBA, Jack Higgins.
- The same book was double-counted because its title was referenced in the review of another book e.g. THE ASSOCIATE was mentioned in the review of THE EXCHANGE, another book by John Grisham. I’m guessing this can be fixed easily by adding a remark in the prompt telling ChatGPT to treat only the entries in the “Name of Book” column as book titles.
- Two different books have the same name! “Row 286, THE INNOCENT by Harlan Coben; Row 469, THE INNOCENT by Sean Black”. I’ve noticed many duplicate books in Goodreads and BookBub. According to Goodreads search results, there are not two or three but 7701 books called THE INNOCENT! (Does this indicate that book titles are not copyrightable?)
I left these entries intact.
3. Self Improvement
As a follow-on to overall summary (insight #3), I asked ChatGPT to plot the distribution of my ratings. It gave me the following chart.
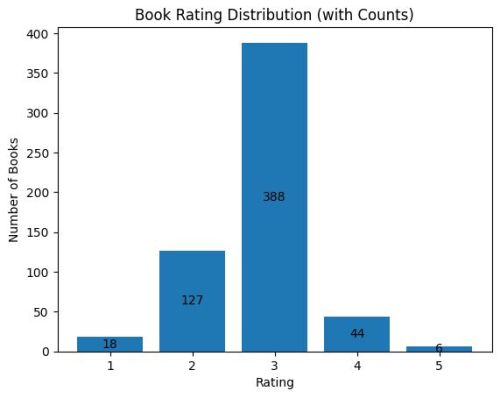
At first blush, this looked like a normal distribution aka bell curve. But ChatGPT disagreed.
No – a normal (bell-curve) distribution would be:
roughly symmetric around the mean, and
have similar frequencies on both sides.
Your distribution is:
strongly peaked at 3 stars
skewed, with sharp drops toward both ends
So it is not normal.
I then asked ChatGPT if it my ratings follow a power law curve.
It first plotted the following log-log chart:
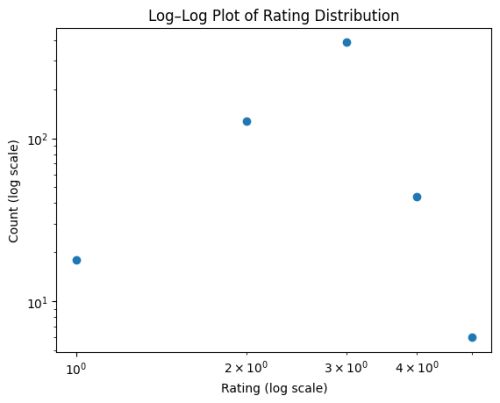
And then said no.
Also no. A power-law distribution would:
- show a straight-ish line on the log–log plot
But your log–log chart bends sharply — the middle category (3★) dominates instead of a smooth decay. That means it does not follow a power-law either.
It felt “this looks like a truncated / central-bias distribution whereby readers mostly rate books as “okay” or “average” and give far fewer “very bad” or “very good” extreme ratings”. Apparently, this pattern is common in subjective rating systems where people avoid extremes.
But it was news to me. I don’t recall coming across such a distribution in the Quant Marketing course during MBA or subsequently in my working career. Ergo the following
Actionable Insight: Learn about truncated / central-bias distribution.
ChatGPT then offered to run a goodness-of-fit test (e.g., normality test), or compare this with Amazon / Goodreads typical rating curves to interpret behavior further. Neither Amazon nor Goodreads existed when I got my MBA degree, so I’m sure I hadn’t studied these tests and curves. Anybody who plans on acting on this insight would need to get a good handle on them, which brings us to the next
Actionable Insight: Learn goodness-of-fit test and comparison with Amazon / Goodreads rating curves.
Coincidentally, as I was writing this post, I was tipped off to a 10-point rating scale used by a leading auto manufacturer in which 1 to 8 is poor, 9 is average and 10 is excellent.
Which “genius” in Indian car industry invented the absurd scale for post-service survey: What is your rating on a scale of 1 to 10, where 1 to 8 is poor, 9 is average, and 10 is excellent?!?
Would love views of mktg experts such as @GTM360 and @beastoftraal
— R_Ganesh (@r_ganesh) December 26, 2025
At first blush, this scale does seem absurd. However, I now wonder if it’s the result of some modern market research technique meant to eliminate the aforementioned truncated / central-bias distribution problem.
This also reminds me that I felt quite weird when I first heard that the highest 5* rating on Uber did not signify superlative experience but merely that “nothing went wrong” during the ride.
4. Entertainment
I got a few surprises in the list of top authors (insight #4): Phillip Margolin, Val McDermid, Jed Rubenfeld, Tom Harper.
As I said before, my Top 3 authors are Joseph Heller, John Irving, and James A. Michener. If you ask me who my Next 7 favorite authors are, none of these four names would figure on that list.
At first blush, I thought ChatGPT was hallucinating. But, then I realized that I’ve indeed read a book or two by these four authors and given them 4* ratings.
When Joseph Heller was asked why he hadn’t written another book like Catch-22, he quipped, “Neither has anybody else”.
Nonetheless I wasn’t able to get my head around these four names and I pushed back by arguing that ChatGPT shouldn’t be selecting top authors based on the ratings of merely two books each. Besides, I also felt that readers pick favorite authors on the basis of their best book written by the said author, not average book.
While my skepticism might still be justified, it also struck me that I’m perhaps behaving like the typical human who overrides data with their biases, which defeats the basic purpose of data analysis. Since I’ve taken the trouble to analyze the data, I thought I must follow through with the results. Ergo the following:
Actionable Insight: Check out a few more books by Phillip Margolin, Val McDermid, and Jed Rubenfeld, Tom Harper.
5. Marketing
Now that ChatGPT has announced that it would enter advertising, it can translate its insights to the following:
Actionable Insight: Send extremely compelling targeted offers for books.
I already receive targeted offers from BookBub based on favorite authors and genres. But this site lacks end-to-end data. BookBub knows that I clicked a book on its email newsletter to visit the online store – e.g. Amazon and Nook – where it’s available at a discount. However, it doesn’t know whether I actually purchased the book there or not, let alone whether I read them.
Even Amazon only knows books bought, not books read.
On the other hand, ChatGPT has a treasure trove of data about my reading preferences. As a result, it can make targeted offers by favorite authors, genres, topics, locales, and other attributes that the current crop of book-selling platforms cannot.
There are at least two ways of evaluating the accuracy of ChatGPT’s data analysis:
- Academic: Crunch the same data in parallel using purpose-built analytics tools like Excel Pivot Table, SAS, Databricks, etc., and compare their results with those provided by ChatGPT, and go from there. This reminds me of selling data entry machines in my early days of tech. To validate the data entered into them, customers would have two people enter the same data on two different DEMs and spot errors by comparing the checksum of the two floppies! This hack worked on the principle that, while two people are equally likely to make mistakes while entering data, they’re highly unlikely to make the same mistake. This is a first principles approach.
- Business: Run a new campaign using ChatGPT’s insights and compare its performance with that of the existing campaign lacking those insights. KPIs for comparison include Conversion Rate and ROAS (Return on Advertising Spend). If the metrics of the ChatGPT-driven campaign trend higher, certify that ChatGPT’s data analysis is accurate enough. In parallel, work with the AI vendor to continually improve the accuracy of the AI model. This is akin to the portfolio approach I described in Evolving Success Metrics For AI.
“To find out whether AI improves efficiency, we could run the same process twice, once the legacy way without AI, and the other with AI, and compare the results” ~ https://t.co/hapEyrOME8.
I can’t recall the last enterprise technology that lent itself to A/B testing like this.— SKR (@s_ketharaman) January 11, 2026
Between this and the previous post, we did a deep dive on the use of ChatGPT to analyze unstructured data, get basic and advanced insights, and suss out actionable insights. We followed the “man in the loop” approach where a human – me! – followed through with the actions triggered by ChatGPT’s insights. In parallel, we noted where ChatGPT could be used to automate the execution of some of its actionable insights. While I didn’t use Agentic AI on this instance, based on my high level exposure to the latest automation technology, I’m reasonably sure that AI Agents will be able to take automation to the next level.